

RAG Application with Cohere Command-R and Rerank
Introduction
The Retrieval-Augmented Generation approach combines LLMs with a retrieval system to improve response quality. However, inaccurate retrieval can lead to sub-optimal responses. Cohere’s re-ranker model enhances this process by evaluating and ordering search results based on contextual relevance, improving accuracy and saving time for specific information seekers. This article provides a guide on implementing Cohere command re-ranker model for document re-ranking, comparing its effectiveness with and without the re-ranker. It uses a pipeline to demonstrate both scenarios, providing insights into how the re-ranker model can streamline information retrieval and improve search tasks.

The article will dive into the use of the Cohere Command, Embedding and Reranker models in document embeddings, responses, and re-ranking. It focuses on the accuracy differences between responses with and without Reranker models. The experiment will use Langchain tools, including the Cohere Reranker implementation, with Nvidia’s Form 10K as input and Deeplake Vector store for document storage.
Learning Objectives
- Learners will grasp the concept of combining large language models with retrieval systems to enhance generated responses by providing additional context.
- Participants will become familiar with Cohere’s reranker model, which evaluates and reorders search results based on contextual relevance to improve the accuracy of responses.
- Students will gain hands-on experience in implementing Cohere’s reranker model for document re-ranking, including setting up a pipeline for document ingestion, query processing, and response generation.
- Participants will learn how to conduct a side-by-side comparison of search results with and without the use of the reranker model, highlighting the difference in response quality and relevance.
- Learners will understand how to integrate various components such as Cohere command , embeddings, Deeplake vector store, and retrieval QA chain to build an effective search and response generation system.
- Students will explore techniques to optimize response generation by tuning prompts and leveraging reranker models to ensure more accurate and contextually appropriate responses.
- Participants will learn about scenarios where the reranker model can significantly improve response accuracy, such as when the vector store contains diverse content or documents of similar kind.
This article was published as a part of the Data Science Blogathon.
Document Retrieval and Question Answering
Let’s obtain our free Cohere API Key before we start with the document ingestion and question answering. First, create an account at Cohere if you don’t have one. Then, generate a Trial key. Go
to this link and generate a Trial key.
Then, let’s setup our development environment for running the experiments. We need to install few packages to run the experiments. Below, install the list of packages required.
cohere==5.2.6
deeplake==3.9.0
langchain==0.1.16
tiktoken==0.6.0
langchain_cohere==0.1.4Once the packages are installed, we are ready to proceed with the experiments. First, we will ingest the document into the vector store. We will be using Deeplake vector store to store the document embeddings.
Step1: Import Libraries
First make the necessary imports. We will need the Deeplake vector store, PyPDFLoader, CharacterTextSplitter, PromptTemplate and RetrievalQA modules from Langchain. We will also import ChatCohere and CohereEmbeddings from langchain_cohere.
from langchain.vectorstores.deeplake import DeepLake
from langchain.document_loaders.pdf import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_cohere import ChatCohere
from langchain_cohere import CohereEmbeddingsStep2: Initializing CohereEmbeddings and DeepLake
Initialize the CohereEmbeddings using the Cohere API key that we generated earlier. Also, mention the name of the embeddings model to be used.
There are several options to chose from. A detailed description of the model in listed here. We will be using the embed-english-v3.0 model to generate the embeddings. Below is the code to initialize the embeddings model and Deeplake vector store using the embeddings.
embeddings = CohereEmbeddings(
model="embed-english-v3.0",
cohere_api_key=API_KEY,
)
docstore = DeepLake(
dataset_path="deeplake_vstore",
embedding=embeddings,
verbose=False,
num_workers=4,
)Here, the trial API key generated earlier serves as the API_KEY, and ‘deeplake_vstore’ denotes the path where the vector store will be created locally.
Step3: Ingesting Document into Vector Store
Now that we have setup the vector store, let’s ingest the document into the vector store. To do this, we will first read the document and split it into chunks of specified size. Below is the code to read the document, split it into chunks and adding them to the vector store.
file = "path/to/document/doc.pdf"
loader = PyPDFLoader(file_path=file)
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
)
pages = loader.load()
chunks = text_splitter.split_documents(pages)
_ = docstore.add_documents(documents=chunks)The code reads a document from its path, splits it into smaller chunks with a 1000 chunk size and 200 chunk overlap to maintain context, and then ingests the chunks into the vectorstore. The ‘add_documents’ method yields a list of chunk IDs, which users can employ to access, delete, or modify specific chunks.
Query Pipeline Setup
With our vector store prepared with ingested documents, we will proceed with the querying pipeline, having imported the necessary dependencies, and will proceed directly with its implementation.
Step1: Initializing DeepLake Vector Store and ChatCohere
First, we will initialize the Deeplake vector store using the path where the vector store is saved and initialize the Cohere model instance.
docstore = DeepLake(
dataset_path="deeplake_vstore",
embedding=embeddings,
verbose=False,
read_only=True,
num_workers=4,
)
llm = ChatCohere(
model="command",
cohere_api_key=API_KEY,
temperature=TEMPERATURE,
)For this experiment we will use the ‘command’ model to generate the responses. We also need to pass the Cohere API key into the model param.
Step2: Creating Retriever Object
Using the vector store instance, we need to create the retriever object. This retriever object will be used to retrieve context for the LLM to answer the user’s queries. Below is the code to create the retriever object
using the vector store.
retriever = docstore.as_retriever(
search_type="similarity",
search_kwargs={
"fetch_k": 20,
"k": 10,
}
)The search type is’similarity’, allowing the retriever to fetch relevant documents using similarity search. The code passes keyword arguments like fetch_k and k, where fetch_k represents the number of relevant documents and k represents the top k. Additionally, a filter field can be added to the search_kwargs parameter for further filtering.
Step3: Defining Prompt Template and Initializing RetrievalQA Chain
Next, we will define the Prompt Template while will be the instruction for the model to generate responses. And then we will initialize the RetrievalQA chain using the model instance, the prompt and few other parameters.
prompt_template = """You are an intelligent chatbot that can answer user's
queries. You will be provided with Relevant context based on the user's queries.
Your task is to analyze user's query and generate response for the query
utiliing the context. Make sure to suggest one similar follow-up question based
on the context for the user to ask.
NEVER generate response to queries for which there is no or irrelevant context.
Context: {context}
Question: {question}
Answer:
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT, "verbose": False}
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
)The code snippet outlines the creation of a PromptTemplate object, which takes in the ‘prompt_template’ variable and a list of keys for inputs. The system is informed that these keys will be passed into the prompt in runtime. The RetrievalQA object is created using the model and retriever, with chain_type set to’stuff’, verbose set to True for debugging, and return_source_documents set to True. This ensures that the response includes a list of Document objects, allowing us to identify the sources used to generate the response.
Step4: Generating a Response to a Query
We have all the necessary components setup to generate response to user query. We will take a query and generate response for that.
query = "What were the fiscal year summaries for year 2023 and 2024? How are they comparable?"
response = qa.invoke({"query": query})
result = response["result"]The qa (RetrievalQA) object retrieves a response for a query. It takes a dictionary containing the query as input to the qa.invoke() method, which requires some time to execute. The response is then stored in the response variable, which allows access to the response using the “result” key and the “source_document” key. For the query response is provided.
The fiscal year 2024 saw a significant increase in revenue, reaching $60.9
billion, up 126% from the previous year. This was driven by strong performance
in the Data Center sector, which alone generated $47.5 billion, a staggering
217% growth. Operating income also experienced a substantial boost, rising to
$32,972 million, compared to $4,224 million in 2023. This translates to an
impressive 681% growth.
In contrast, fiscal year 2023 showed slower progress, with revenue remaining
flat at $26.97 billion. Both operating and net income declined by 58% and
55% respectively compared to the previous year.
The two years are comparable in that they represent consecutive fiscal periods
and showcase the company's evolving financial health.
A follow-up question could be: What factors contributed to the substantial
growth in the Data Center revenue in fiscal year 2024?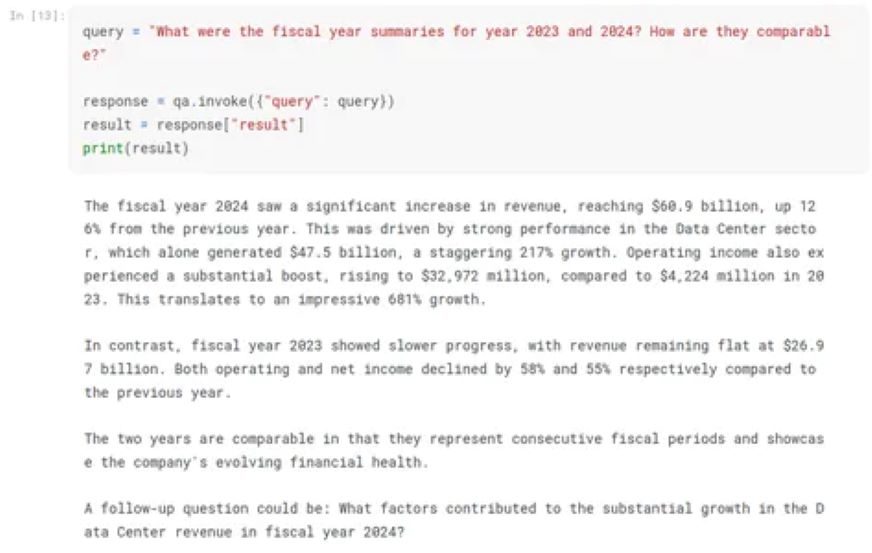
The response that the model gave is correct and to the point. Now let’s see how the reranker can help get better response.
Implementing Cohere’s Reranker Model
Step1: Importing Necessary Modules
First, we need to import two modules that are necessary to use reranker retriever in our pipeline.
from langchain.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerankContextualCompressionRetriever will be used as a wrapper around the vector store retriever and will help compress the retrieved documents after reranking. CohereRerank is necessary to create the reranker object.
Step2: Creating the Reranker Object and Compression Retriever
Now, we need to create the reranker object, then use it in the Retriever compressor.
cohere_rerank = CohereRerank(
cohere_api_key=API_KEY,
model="rerank-english-v3.0",
)
docstore = DeepLake(
dataset_path="deeplake_vstore",
embedding=embeddings,
verbose=False,
read_only=True,
num_workers=4,
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=cohere_rerank,
base_retriever=docstore.as_retriever(
search_type="similarity",
search_kwargs={
"fetch_k": 20,
"k": 15,
},
),
)The CohereRerank object is created using the Cohere API key and reranker model name, initialized using previous configurations, and initialized with the Compression Retriever object. The cohere_rerank object is passed and a retriever instance is created using the vector store instance.
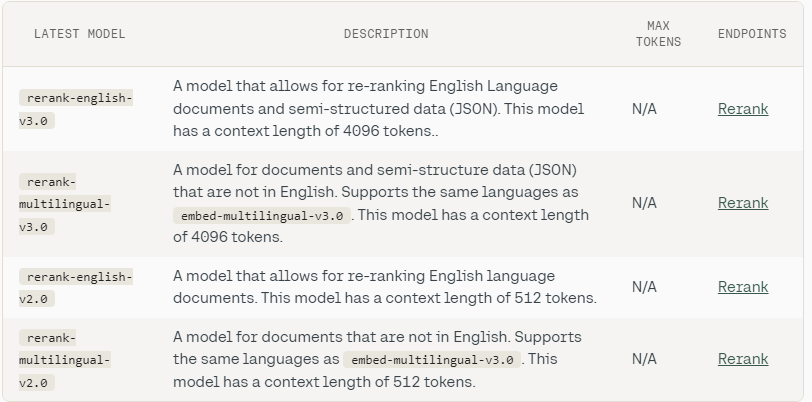
There are few other choices of reranker model, which can be used based on the use-case. Here are the list of other Reranker models to chose from.
Step3: Setting up QA (RetrievalQA) Object with the Reranker
Next, we need to setup the qa (RetrievalQA) object with the prompt template, just like we did for the qa pipeline without reranker. The only change we need here is the retriever being replaced with compression_retriever.
prompt_template = """You are an intelligent chatbot that can answer user's
queries. You will be provided with Relevant context based on the user's queries.
Your task is to analyze user's query and generate response for the query
utiliing the context. Make sure to suggest one similar follow-up question based
on the context for the user to ask.
NEVER generate response to queries for which there is no or irrelevant context.
Context: {context}
Question: {question}
Answer:
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT, "verbose": False}
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=compression_retriever,
return_source_documents=True,
verbose=False,
chain_type_kwargs=chain_type_kwargs,
)Step4: Generating a response to a query with the reranker
Finally, we will use the qa object to invoke the LLM on the user query.
query = "What were the fiscal year summaries for year 2023 and 2024? How are they comparable?"
response = qa.invoke({"query": query})
result = response["result"]After running the above code, we get the response from LLM. We can print the response by printing ‘result’. Below is the LLM response for the query asked:
The fiscal year 2023 ended on January 29, 2023, and the fiscal year 2024 began
on January 30, 2023. The summary for fiscal year 2023 shows revenue of $26,974
million with a 56.9% gross margin, while fiscal year 2024's summary is not
mentioned in the context provided.
The operating expenses for fiscal year 2023 saw a rise of 50% to reach
$11,132 million due to acquisition termination charges and other operational
costs. Conversely, fiscal year 2022's operating expenses were $7,434 million.
Net income and income from operations witnessed a downward trend in fiscal year
2023 compared to the previous year. Fiscal year 2023 reported net income of
$4,368 million and income from operations of $4,224 million. Meanwhile, fiscal
year 2022 recorded figures of $9,752 million and $10,041 million,
respectively.
With a change in accounting estimate, the depreciation expense for fiscal year
2024 is expected to decrease, thereby increasing operating income by $133
million.
An analysis of the fiscal year 2023 and 2024 summaries indicates a contrast in
financial performance, primarily due to the expenses incurred in 2023.
Follow-up question: How did the change in accounting estimate impact the fiscal
year 2024 financial summary, especially regarding revenue and operating
expenses?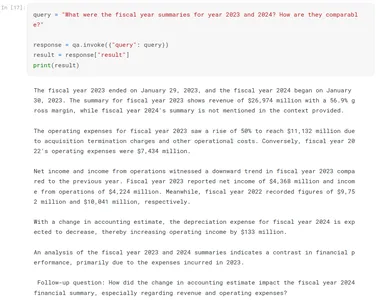
As we can see, the response after using reranker is more comprehensive and engaging. We can further customize the response by tuning the prompt based on how we want the response to be.
Conclusion
The article discusses the application of Cohere’s re-ranker model in document re-ranking, highlighting its significant improvement in accuracy and relevance. The re-ranker model refines information retrieval and contributes to more informative and contextually appropriate responses, enhancing the overall search experience and reliability of RAG-enabled systems. The article also discusses the modularization of the pipeline to create a document chatbot with chat memory accessibility and a Streamlit app for seamless interaction with the chatbot. In this we learned RAG application with cohere command-R and rerank-Part 1.
Key Takeaways
- Cohere command re-ranker model enhances response accuracy by reordering search results based on contextual relevance.
- The article guides readers in implementing Cohere’s re-ranker model for document re-ranking, improving search tasks.
- Integrating Cohere’s re-ranker model significantly improves the accuracy and relevance of responses in the RAG approach.
- Part 2 of the article will focus on modularization and Streamlit app development for enhanced user interaction.
- The Reranker model improves response accuracy, especially in scenarios with diverse content or similar documents.
- Cohere’s re-ranker model is compatible with OpenAI’s API, enhancing QnA pipelines.
- While effective, there may be slight response inconsistencies, addressable through prompt tuning.
Limitations
While the application works well, and the responses are quiet accurate, there can be few inconsistencies in the responses. But those inconsistencies can be handled by tuning the prompt according to desired response. We have used Cohere Command-R model for this experiment. The other two models can also be used if desired.
Frequently Asked Questions
A. In cases where the vector store contains contents of many documents of similar kind, the model might generate responses that are irrelevant with the queries. The reranker model helps to rerank the retrieved documents based on the user’s query. This helps the model generate accurate response.
A. Yes. You can use the reranker module to wrap the vector store retriever object and integrate it into the Retrieval QA chain, which utilizes OpenAI’s GPT models.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.